要想保证在服务器宕机的情况下网站依然可以继续服务,不丢失数据,就需要一定程度的服务器冗余运行,数据冗余备份。将多台服务器部署相同应用构成1个集群,通过负载均衡设备共同对外提供服务,这样当某台服务器宕机,可以将其上的服务和数据服务转移到其他机器上。访问和负载很小的服务也需要部署至少两台服务器构成一个集群,其目的就是通过冗余实现服务高可用。
1. 负载均衡
负载均衡是高可用实现的手段,所有的请求都要经过负载均衡系统完成请求的转发。在集群中,这种方式对于发起请求一方以为是中间的代理提供了服务,而处理请求的一方会以为是中间的代理请求的服务。发起的一方不用关心有多少台机器提供服务,也不需要知道这些提供服务的地址,只需要知道中间透明代理的地址就行了。
主要有2个不足:
- 增加网络的开销,一方面增加了流量,另一方面是增加了延迟。
- 代理处于必经之路,如果代理出现了问题,所有的请求都会受到影响。
数据包小的情况下,代理模式只有很小的流量增加,如果数据包很大,流量增加还是比较明显的。延时方面,结构上会有这个影响,但是实际影响很小。总体来说,这是一种非常方便、直观的方案。
一般的应用场景页面不需要负载均衡的,因为浏览器将html及静态资源下载到本地后,都是由浏览器直接发送异步请求到后端服务器的。对nginx的压力相对还是比较小的。对于请求量很大的情况,使用cdn是更好的方案。
1.1 keepalived
Keepalived是一个基于VRRP协议来实现的服务高可用方案,可以利用其来避免IP单点故障,类似的工具还有heartbeat、corosync、pacemaker。但是它一般不会单独出现,而是与其它负载均衡技术(如lvs、haproxy、nginx)一起工作来达到集群的高可用。 VRRP全称 Virtual Router Redundancy Protocol,即虚拟路由冗余协议。可以认为它是实现路由器高可用的容错协议,即将N台提供相同功能的路由器组成一个路由器组(Router Group),这个组里面有一个master和多个backup,但在外界看来就像一台一样,构成虚拟路由器,拥有一个虚拟IP(vip,也就是路由器所在局域网内其他机器的默认路由),组内的路由器根据优先级,选举出Master路由器,占有这个虚拟IP,承担网关功能。其他路由器作为Backup路由器,当Master路由器发生故障时,取代Master继续履行网关职责,从而保证网络内的主机不间断地与外部网络进行通信。
global_defs {
notification_email {
user@example.com
}
notification_email_from mail@example.org
smtp_server 192.168.200.1
smtp_connect_timeout 30
router_id LVS_DEVEL
}
vrrp_script chk_nginx {
script "/etc/keepalived/check_nginx.sh"
interval 2
weight -5
fall 3
rise 2
}
vrrp_instance VI_1 {
state MASTER #标示状态为MASTER, 如果备用的写 BACKUP
interface eth0
virtual_router_id 51
priority 101 #MASTER权重要高于BACKUP
advert_int 1
mcast_src_ip 192.168.88.147 #vrrp实体服务器的IP
authentication {
auth_type PASS #主从服务器验证方式
auth_pass 1111
}
#VIP
virtual_ipaddress {
192.168.88.99 #虚拟IP
}
track_script {
chk_nginx
}
}
备用节点写将state MASTER 改为BACKUP。通过vrrp_script可以检查负载均衡服务的状态。
1.2 haproxy
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
global
daemon
defaults
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend http-in
bind *:18080
default_backend servers
backend servers
server server1 192.168.88.210:18080 check
server server2 119.3.36.108:18080 check
listen stats
bind-process 1
bind :29010
stats enable
stats uri /
stats auth demo:demo
stats realm Demo
stats admin if TRUE
docker-compose:
1
2
3
4
5
6
7
haproxy:
image: haproxy:1.9
volumes:
- E:/daily-using/haproxy:/usr/local/etc/haproxy
ports:
- "21000:18080"
- "29010:29010"
- frontend: 监听端口、协议代理定义,HTTP认证,后端选择等;
- backend: 监控server,负载均衡,队列。 可以看出,在frontend 中定义了要绑定的地址和端口,以及证书等,在backend,罗列了后端的IP和端口。
- 不过要把2者合在一起写,也是可以的, 如stats, TCP-only 非常有用。
1.3 nginx
1
2
3
4
5
6
7
8
9
10
nginx:
image: nginx:1.15
container_name: nginx
volumes:
- E:/daily-using/nginx/conf.d:/etc/nginx/conf.d
ports:
- "30080:80"
- "30081:30081"
environment:
- NGINX_PORT=80
首先,把容器里面的 Nginx 配置文件拷贝到本地。
1
docker container cp nginx:/etc/nginx/conf.d .
增加负载均的配置:
upstream lb_backends {
server 192.168.88.210:18080;
server 119.3.36.108:18080;
keepalive 2000;
}
server {
listen 80;
server_name localhost;
#charset koi8-r;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
location /backend/ {
proxy_pass http://lb_backends/;
proxy_set_header Host $host:$server_port;
}
}
访问的地址加上/backend会自动选择nginx的负载均衡了。
1.4 Spring cloud负载均衡
Spring cloud zuul和feign都集成了ribbon,实现请求的负载均衡。
Spring cloud Ribbon的作用是负载均衡,会帮助我们在每次请求时选择一台机器,均匀的把请求分发到各个机器上Ribbon的负载均衡默认使用的最经典的Round Robin轮询算法。这是啥?简单来说,就是如果订单服务对库存服务发起10次请求,那就先让你请求第1台机器、然后是第2台机器、第3台机器、第4台机器、第5台机器,接着再来—个循环,第1台机器、第2台机器。。。以此类推。
以feign的负载均衡为例,此外,首先Ribbon会从 Eureka Client里获取到对应的服务注册表,也就知道了所有的服务都部署在了哪些机器上,在监听哪些端口号。然后Ribbon就可以使用默认的Round Robin算法,从中选择一台机器,Feign就会针对这台机器,发起请求。
2. Eureka高可靠
eureka([jʊ’rikə]) server的高可靠还是比较容易的,只需要在defaltZone中写上其他eureka server的地址就可以了。
1
2
3
4
5
6
7
8
9
10
server:
port: 8100
eureka:
instance:
hostname: server1
instance-id: ${spring.application.name}:${server.port}
client:
service-url:
defaultZone: http://server2:${port}/eureka,http://server3:${port}/eureka
eureka client 服务向eureka server集群注册也是比较简单的,只需要在defaultZone中指定所有eureka-server的地址就可以了:
1
2
3
4
5
6
7
8
9
10
11
12
server:
port: 8001
spring:
application:
name: "service-provider-demo"
eureka:
instance:
prefer-ip-address: true
client:
service-url:
defaultZone: http://server1:${port}/eureka/,http://localhost:8200/eureka/,http://localhost:8300/eureka/
其他服务的高可靠都是基于eureka的,包括配置中心,其他服务都通过eureka请求的地址,访问其他服务。
3. 熔断
在微服务架构中通常会有多个服务层调用,基础服务的故障可能会导致故障传递,进而造成整个系统不可用的情况,这种现象被称为服务雪崩效应。服务雪崩效应是一种因“服务提供者”的不可用导致“服务消费者”的不可用,并将不可用逐渐放大的过程。
因为熔断只是作用在服务调用这一端,所以只需要打开feign的hystrix的开关,通过@HystrixCommand设置fallback就可以了。
4. 多实例带来的问题
4.1 定时任务
每个实例都出发定时任务会导致定时任务重复出发。单独一个服务出发定时任务就可以了。
4.2 分布式锁
由于多个实例会同时执行,原来的synchronized等锁需要替换为分布式锁。
4.3 分布式事务
通过2阶段提交的方式解决,但是实现起来比较复杂,通过补偿的方式,达到最终一致性。
4.4 消息队列消费
4.4.1 kafka
消息队列消费需要保证多实例后,每个实例不消费已经被消费大的数据,对于kafka是可以是指消费组的, 一个Partition只允许被一个消费组中的一个消费者所消费。得出的结论是:在一个消费组中,一个消费者可以消费多个Partition,不同的消费者消费的Partition一定不会重复,所有消费者一起消费所有的Partition;在不同消费组中,每个消费组都会消费所有的Partition。也就是同一个消费组下消费者对Partition是互斥的,而不同消费组之间是共享的。比如有两个消费者订阅了一个topic,如果这两个消费者在不同的消费组中,则每个消费者都会获取到这个topic所有的记录;如果这两个消费者是在同一个消费组中,则它们会各自获取到一半的记录(两者的记录是对半分的,而且都是不重复的)
4.4.2 EMQ
EMQ支持队列共享订阅和分组共享订阅的方式,保证共享订阅的消息只会到达一个或者每组中的一个订阅客户端。
5. 高可用性架构举例
5.1 主备倒换式的高可靠架构
如果只有单个服务的情况,流量也不大,只要保证服务器出问题的时候,可以进行切换就可以了。
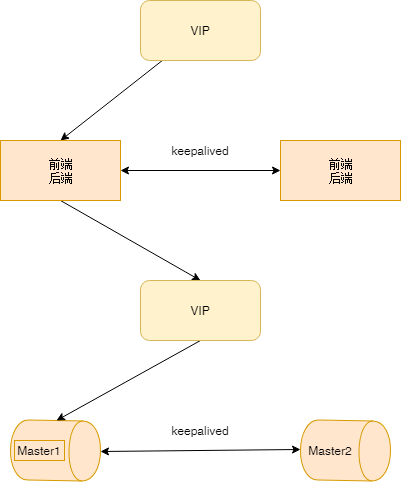
- 将前/后端服务部署在同一个服务器上,数据库单独部署。甚至可以将前/后端和数据库都部署在一起。
- 将所有服务在另一台服务器上部署一份,相同的服务之间的服务器通过keepalive提供虚拟IP对外提供服务。
- 数据之间通过服务 进行数据通过。
5.2 具有负载均衡的高可用
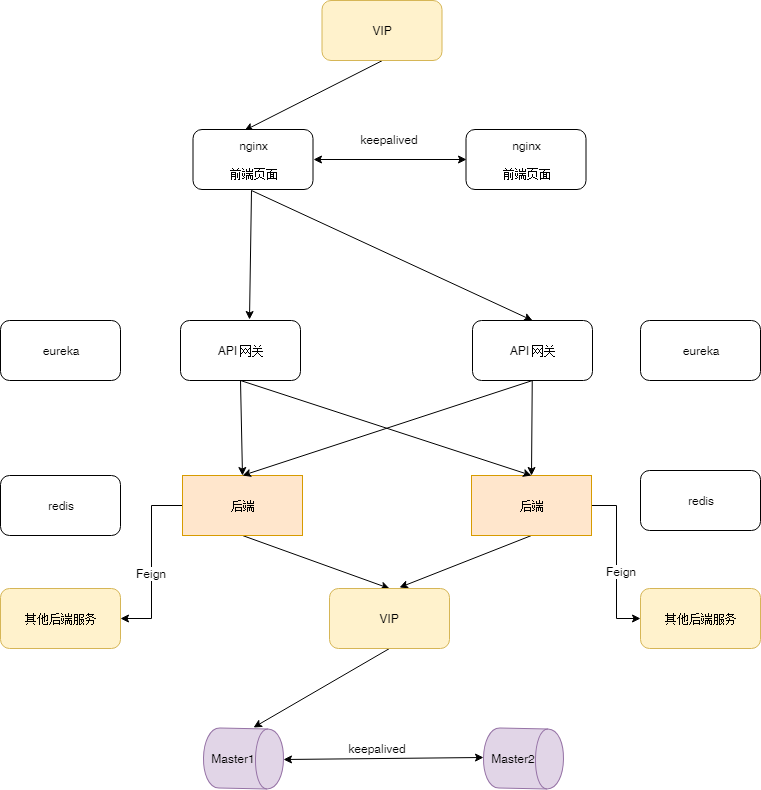
如果服务很多,而且已经上了spring cloud, 使用具有负载均衡的方案还是比较合适的。
- nginx通过keepalive提供的虚拟IP对外提供服务
- 前端页面的请求都通过经过nginx负载均衡后,通过API网关请求后端服务。
- API网关作为eureka的client向eureka server集群注册。
- API网关将前端请求通过负载均衡分发到对应的后端服务。
- 所有后端服务之间的引用封装feign的jar访问其他服务,达到负载均衡的目的。
- 数据库通过主从复制,实现接近实时的数据备份,并且通过keepalive提供的虚拟IP对外提供服务。
- 通过redis实现分布式锁
6. 全生命周期考虑
- 预防:建立常态的压力体系,例如上线前的单机压测到上线后的全链路压测
- 管控: 做好线上运行时的降级(牺牲次要功能和用户体验保证核心业务的稳定)、限流(限制一部分流量)和兜底保护
- 监控:建立性能基线来记录性能的变化趋势以及线上机器的负载报警体系,发现问题及时预警
- 恢复体系:遇到故障要及时止损,并提供快速的数据订正工具