1 什么是微服务
微服务就是一些协同工作的小而自治的服务。
- 很小,专注于做好一件事,单一职责原则
- 自治性
如果系统没有很好地解耦,那么一旦出现问题,所有的功能都将不可用。有一个黄金法则是:你是否能够修改一个服务并对其进行部署,而不影响其他任何服务。
1.1 好处
- 技术异构,每个服务选择最合适的技术
- 稳定性和容错能力变强(弹性),某个服务出现问题,不会所有功能不可用。
- 扩展性增强
- 简化部署,不同的服务单独部署,快速上线,快速回滚
- 与组织结构相匹配,小型代码库上工作的团队更加高效。
- 可组合性和重用性。
- 重构,可以相对比较容易的重写或者删除某个服务。
小型的,简单的和解耦的服务 = 可伸缩的、有弹性的和灵活的应用程序。
2 演进的架构
架构师必须改变那种从一开始就要设计出完美产品的想法,相反我们应该设计出一个合理的框架,在这个框架下可以慢慢演化出正确的系统,并且一旦我们学到了更多知识,应该可以很容易地应用到系统中。
架构师的职责之一就是保证该系统适合开发人员在其上工作。他们需要保证系统不但能够满足当前的需求,还能够应对将来的变化。而且他们还应该保证在这个系统上工作的开发人员要和使用这个系统的用户一样开心。
2.1 边界
作为架构师,应该考虑不同的服务之间如何交互,或者说保证我们能够对整个系统的健康状态进行监控。至于多大程度地介入区域内部事务,在不同的情况下则有所不同。很多组织采用微服务是为了使团队的自治性最大化,
架构师和团队真正坐在一起,这件事情再怎么强调也不过分!至于和团队在一起工作的频率可以取决于团队的大小,关键是它必须成为日常工作的一部分。
2.2 愿景
愿景 指导系统演化。
“规则对于智者来说是指导,对于愚蠢者来说是遵从。”—— 一般认为出自Douglas Bader
可能需要花费更多的时间和组织内非技术的部分(通常他们被叫作业务部门)进行交互。那么业务部门的愿景是什么?它又会如何发生改变呢?
为了和更大的目标保持一致,我们会制定一些具体的规则,并称之为原则,它不是一成不变的。举个例子,如果组织的一个战略目标是缩短新功能上线的周期,那么一个可能的原则是,交付团队应该对整个软件生命周期有完全的控制权,这样他们就可以及时交付任何就绪的功能,而不受其他团队的限制。
很有可能这些原则并不适合你的组织。一般来讲,原则最好不要超过10个,或者能够写在一张海报上,不然大家会很难记住。原来华三的TOP10问题就是一个很好的方法,并且印在了一张海报上贴在每个办公区域。
2.3 规范
规范用于指导实施细节,从而实现这些原则。如编码规范,日志规范,HTTP/REST规范等。这些规范一般比较偏技术层面,所以改变的频率会高于原则。
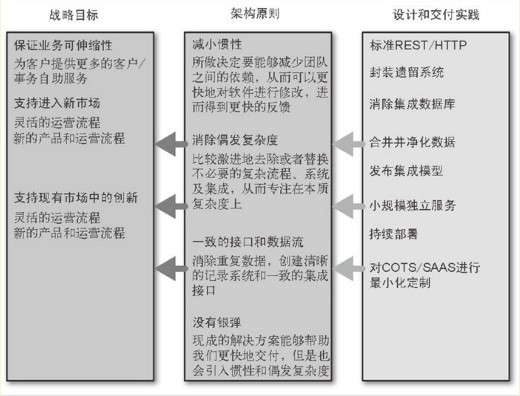
2.4 一个好服务应该有的属性
1.监控,统一的状态收集,监控,日志也是。
2.接口,REST使用动词还是名词,如何处理分页,API的版本如何处理。返回码需要统一。
3.架构的安全性, 防止一个服务出现问题导致整个系统雪崩。
2.5 代码治理
2.5.1 代码样例
提供优秀的代码样例用于参考。
2.5.2 代码模板
如果能够让所有的开发人员很容易地遵守大部分的指导原则,那就太棒了。一种可能的方式是,当开发人员想要实现一个新服务时,所有实现核心属性的那些代码都应该是现成的。
举个例子,如果你想要断路器的规范化使用,那么就可以将Hystrix这个库集成进来。或者,你想要把所有的指标数据都发送到中心Graphite服务器,那么就可以使用像Dropwizard’s Metrics这样的开源库,只需要在此基础上做一些配置,响应时间和错误率等信息就会自动被推送到某个已知的服务器上。针对自己的开发实践裁剪出一个服务代码模板,不但可以提高开发速度,还可以保证服务的质量。
当然,如果你的组织使用多种不同的技术栈,那么针对每种技术栈都需要这样一个服务代码模板。你也可以把它当作一种在团队中巧妙地限制语言选择的方式。如果只存在基于Java的服务代码模板,那么选用其他技术栈就意味着开发人员需要自己做很多额外的工作。Netflix非常在意服务的容错性,因为它们不希望一个服务停止工作造成整个系统都无法正常工作。Netflix提供了一个基于JVM的库来处理这些问题。任何一个新技术栈的引入都意味着要把这部分工作重新做一遍。相对于做这些事情的代价,Netflix更关心的是,开发这些库时可能会引入的错误。如果某个新实现的服务的容错处理机制出错,其对系统带来严重影响的风险也会增加。
我也见过一个团队的士气和生产力是如何被强制使用的框架给毁掉的。基于代码重用的目的,越来越多的功能被加到一个中心化的框架中,直至把这个框架变成一个不堪重负的怪兽。如果你决定要使用一个裁剪的服务代码模板,一定要想清楚它的职责是什么。理想情况下,应该可以选择是否使用服务代码模板,但是如果你强制团队使用它,一定要确保它能够简化开发人员的工作,而不是使其复杂化。
2.6 集中治理和领导
他们需要确保有一组可以指导开发的原则,并且这些原则要与组织的战略相符。他们还需要确保,以这些原则为指导衍生出来的实践不会给开发人员带来痛苦。他们需要了解新技术,需要知道在什么时候做怎样的取舍。上述这些职责已经相当多了,但是他们还需要让同事也理解这些决定和取舍,并执行下去。对了,还有前面提到的:他们还需要花时间和团队一起工作,甚至是编码,从而了解所做的决定对团队造成了怎样的影响。
这个小组应该由技术专家领导,并且要有一线人员的参与。这个小组也应该负责跟踪和管理技术风险。我很喜欢的一种模式是,由架构师领导这个小组,但是每个交付团队都有人参加。架构师负责确保该组织的正常运作,整个小组都要对治理负责。
有时候架构师可能不认同小组做的决定,这时应该怎么办?我曾经面对过这样的场景,我认为这是架构师需要面对的最富有挑战性的场景之一。事实上,大多数情况下我会认同小组的决定。我曾经尝试说服大家,但事实证明这很难做到。一个小组通常会比单个人更加聪明,而且我也不止一次被证明是错误的!如果你给一个小组权力去做决定,但在最后又忽略了这个决定,那这个小组就毫无意义可言了。有时候我也会对小组施加影响。
类比一下教小孩儿骑自行车的过程。你没法替代他们去骑车。你会看着他们摇摇晃晃地前行,但是,如果每次你看到他们要跌倒就上去扶一把,他们永远都学不会。而且无论如何,他们真正跌倒的次数会比你想象的要少!但是,如果他们马上就要驶入车流繁忙的大马路,或者附近的鸭子池塘,你就必须站出来了。类似地,作为一名架构师,你必须要在团队驶向类似鸭子池塘这样的地方时抓紧他们。
2.7 团队建设
对于一个系统技术愿景的主要负责人来说,执行愿景不仅仅等同于做技术决定,和你一起工作的那些人自然会做这些决定。对于技术领导人来说,更重要的事情是帮助你的队友成长,帮助他们理解这个愿景,并保证他们可以积极地参与到愿景的实现和调整中来。
我坚定地相信,伟大的软件来自于伟大的人。所以如果你只担心技术问题,那么恐怕你看到的问题远远不及一半。
演进式架构师应该理解,成功要靠不断地取舍来实现。总会存在一些原因需要你改变工作的方式,但是具体做哪些改变就只能依赖于自己的经验了。而僵化地固守自己的想法无疑是最糟糕的做法。虽然本章的大部分建议对任何一个系统架构师来说都适用,但是在微服务系统中,架构师需要做更多的决定,因此,能更好地平衡这些取舍是非常关键的。
3 如何建模服务
好服务:高内聚,低耦合
3.1 松耦合
使用微服务最重要的一点是,能够独立修改及部署单个服务而不需要修改系统的其他部分,这真的非常重要。一个松耦合的服务应该尽可能少地知道与之协作的那些服务的信息。这也意味着,应该限制两个服务之间不同调用形式的数量,因为除了潜在的性能问题之外,过度的通信可能会导致紧耦合。
找到问题域的边界就可以确保相关的行为能放在同一个地方,并且它们会和其他边界以尽量松耦合的形式进行通信。
Evans使用细胞作为比喻:“细胞之所以会存在,是因为细胞膜定义了什么在细胞内,什么在细胞外,并且确定了什么物质可以通过细胞膜。”
- 避免过早划分,进入一个新的领域,过早划分会导致后续跨服务的修改,不确定划分的时候,可以先用一个服务,将已有代码划分成微服务比从头开始构建微服务简单的多。
- 基于功能考虑数据模型
- 组织架构和服务架构会相互影响(康威原则)
内部表示暴露给了我们的消费方,而且很难做到无破坏性的修改,进而不可避免地导致不敢做任何修改,所以无论如何都要避免这种情况。
使用协同方式,在这种方式下每个服务都足够聪明,并且能够很好地完成自己的任务。这里有好几个因素需要考虑。同步调用比较简单,而且很容易知道整个流程的工作是否正常。如果想要请求/响应风格的语义,又想避免其在耗时业务上的困境,可以采用异步请求加回调的方式。
分布式计算中一个非常著名的错误观点就是“网络是可靠的”,事实上网络并不可靠。即使客户端和服务端都正常运行,整个调用也有可能会出错。这些错误有可能会很快发生,也有可能会过一段时间才会显现出来,它们甚至有可能会损坏你的报文。
先设计外部接口,等到外部接口稳定之后再实现微服务内部的数据持久化。
对于服务和服务之间的通信来说,如果低延迟或者较小的消息尺寸对你来说很重要的话,那么一般来讲HTTP不是一个好主意。你可能需要选择一个不同的底层协议,比如UDP(UserDatagramProtocol,用户数据报协议)来满足你的性能要求。很多RPC框架都可以很好地运行在除了TCP之外的其他网络协议上。
3.2 异步通信
如果你的系统通过消息队列进行通信,那么你需要过滤(由不同步的部署导致的)失效的内容,忘记这么做会引起严重的问题。跨服务共用代码很有可能会引入耦合。但使用像日志库这样的公共代码就没什么问题,因为它们对外是不可见的。
3.3 按引用访问
考虑这样一个例子:发货之后需要请求邮件服务来发送一封邮件。一种做法是,把客户的邮件地址、姓名、订单详情等信息发送到邮件服务。但是邮件服务有可能会将这个请求放入队列,然后在将来的某个时间再从队列中取出来,在这个时间差中,客户和订单的信息有可能就会发生变化。更合理的方式应该是,仅仅发送表示客户资源和订单资源的URI,然后等邮件服务器就绪时再回过头来查询这些信息。在考虑基于事件的协作时,你会发现一个很棒的对位(counterpoint)。使用事件时,不仅需要知道该事件是否发生,还需要知道到底发生了什么。所以当收到一个客户资源变化的更新事件时,我想要知道事件发生时该客户的状态。同时为了能够在处理事件时得到资源的最新状态,也应该拥有该实体的引用以便于查询。
稳定和容错能力:该法则认为,系统中的每个模块都应该“宽进严出”,即对自己发送的东西要严格,对接收的东西则要宽容。这个原则最初的上下文是网络设备之间的交互,因为在这个场景中,所有奇怪的事情都有可能发生。
4 使用语义化的版本管理
在同一个服务上使新接口和老接口同时存在。所以在发布一个破坏性修改时,可以部署一个同时包含新老接口的版本。 为了使其更可控,我们在内部把所有对V1的请求进行转换处理,然后去访问V2,继而V2再去访问V3。
这其实就是一个扩展/收缩模式的实例,它允许我们对破坏性修改进行平滑的过度。首先扩张服务的能力,对新老两种方式都进行支持。然后等到老的消费者都采用了新的方式,再通过收缩API去掉旧的功能。
对于一般规模的组织来说,如果某个软件非常特殊,并且它是你的战略性资产的话,那就自己构建;如果不是这么特别的话,那就购买。
没有什么是不能通过封装一层解决的:
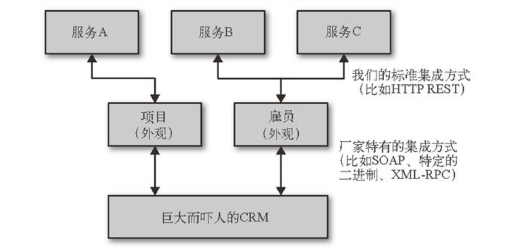
由于多个其他的系统需要项目的信息,所以我们就创建了项目服务。这个服务将项目以RESTful资源的形式暴露出来,外部系统可以把它们的集成点迁移到这个新的、易用的服务上来,而这个项目服务仅仅是隐藏了底层的集成细节而已。
绞杀者模式:与在CMS系统前面套一层自己的代码非常类似,绞杀者可以捕获并拦截对老系统的调用。这里你就可以决定,是把这些调用路由到现存的遗留代码中还是导向新写的代码中。这种方式可以帮助我们逐步对老系统进行替换,从而避免影响过大的重写。