1 消息中间件对比
消息中间件大道至简:一发一存一消费,没有最好的消息中间件,只有最合适的消息中间件。 消息中间件用于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下提供应用解耦、弹性伸缩、冗余存储、流量削峰、异步通信、数据同步等等功能,其作为分布式系统架构中的一个重要组件,有着举足轻重的地位。
ActiveMQ 是 Apache 出品的、采用 Java 语言编写的完全基于 JMS1.1 规范的面向消息的中间件,为应用程序提供高效的、可扩展的、稳定的和安全的企业级消息通信。不过由于历史原因包袱太重,目前市场份额没有后面三种消息中间件多,其最新架构被命名为 Apollo,号称下一代 ActiveMQ,有兴趣的同学可行了解。
RabbitMQ 是采用 Erlang 语言实现的 AMQP 协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。RabbitMQ 发展到今天,被越来越多的人认可,这和它在可靠性、可用性、扩展性、功能丰富等方面的卓越表现是分不开的。
Kafka 起初是由 LinkedIn 公司采用 Scala 语言开发的一个分布式、多分区、多副本且基于 zookeeper 协调的分布式消息系统,现已捐献给 Apache 基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如 Cloudera、Apache Storm、Spark、Flink 等都支持与 Kafka 集成。
RocketMQ 是阿里开源的消息中间件,目前已经捐献个 Apache 基金会,它是由 Java 语言开发的,具备高吞吐量、高可用性、适合大规模分布式系统应用等特点,经历过双 11 的洗礼,实力不容小觑。
ZeroMQ 号称史上最快的消息队列,基于 C 语言开发。ZeroMQ 是一个消息处理队列库,可在多线程、多内核和主机之间弹性伸缩,虽然大多数时候我们习惯将其归入消息队列家族之中,但是其和前面的几款有着本质的区别,ZeroMQ 本身就不是一个消息队列服务器,更像是一组底层网络通讯库,对原有的 Socket API 上加上一层封装而已。
1.1 社区活跃程度
截止到2019年6月16日:
- ActiveMQ 只有1479个Star, 1042个fork, 下一代架构apollo最近几年都没有更新过代码
- kafka有12435个Star, 6673个fork,最近几天有代码更新
- RabbitMQ有5861 star, 1717个fork,最近几天有代码更新
- RocketMQ有8066个star,4106个fork,最近20天以前才有代码更新。
1.2 性能
功能维度是消息中间件选型中的一个重要的参考维度,但这并不是唯一的维度。有时候性能比功能还要重要,况且性能和功能很多时候是相悖的,鱼和熊掌不可兼得,Kafka 在开启幂等、事务功能的时候会使其性能降低,RabbitMQ 在开启 rabbitmq_tracing 插件的时候也会极大的影响其性能。消息中间件的性能一般是指其吞吐量,虽然从功能维度上来说,RabbitMQ 的优势要大于 Kafka,但是 Kafka 的吞吐量要比 RabbitMQ 高出 1 至 2 个数量级,一般 RabbitMQ 的单机 QPS 在万级别之内,而 Kafka 的单机 QPS 可以维持在十万级别,甚至可以达到百万级。
1.3 可靠性
想要找到一个产品来保证消息的绝对可靠,很不幸的是这世界上没有绝对的东西,只能说尽量趋于完美。想要尽可能的保障消息的可靠性也并非单单只靠消息中间件本身,还要依赖于上下游,需要从生产端、服务端和消费端这 3 个维度去努力保证,
2 简介
版本演进:
- 0.7, 上古版本,只提供了最基础的消息队列功能,连副本机制都没有,不建议使用。
-
0.8, 正式引入副本机制,比较好的做到消息无丢失,消费者和生产者的API还是指定ZooKeeper大的地址。0.8.2.0正式引入了新盘本的Producer API,即指定Borker地址。建议使用新版本,如果不能升级,也建议使用0.8.2.2大的老本的API。因为新版本API的bug非常多。
- 0.9, 2015年11月,正式发布了0.9.0.0版本。增加了基础的安全认证/权限功能,同时引入了kafka connecty用于实现高性能的数据抽取。新版本Prodeucer API已经比较稳定了,但是新版Cunsumer API BUG超级多,不要使用。
- 0.10, 引入kafka Sreams。0.10.2.2的新版本Consumer API已经稳定了,同时修复了导致Producer性能降低的Bug.
- 0.11, 2017年6月社区发布了0.11.0.0版本,提供了幂等性Producer API以及事务API,同时对消息格式进行了重构。这个版本中各个大功能组件都变得非常稳定了,这个版本的用户很多。建议升级到0.11.0.3,因为这个版本呢的消息引擎功能已经非常完善了。
- 1.0和2.0, 2017年11月发布了1.0, 2018年6月发布了2.0, 这2个版本都是kafka streams的改进,在消息引擎方面并未引入太多的功能特性。
不论使用的哪个版本,都请尽量保持服务端版本和客户端版本呢一致,否则将损失很多kafka的性能优化。
kafka支持3种消息投递语义:
- At most once——最多一次,消息可能会丢失,但不会重复
- At least once——最少一次,消息不会丢失,可能会重复
- Exactly once——有且只有一次,消息不丢失不重复,只且消费一次。
但是整体的消息投递语义需要Producer端和Consumer端两者来保证。
2.1 Producer 消息生产者端
一个场景例子: 当producer向broker发送一条消息,这时网络出错了,producer无法得知broker是否接受到了这条消息。网络出错可能是发生在消息传递的过程中,也可能发生在broker已经接受到了消息,并返回ack给producer的过程中。
这时,producer只能进行重发,消息可能会重复,但是保证了at least once。
0.11.0的版本通过给每个producer一个唯一ID,并且在每条消息中生成一个sequence num,这样就能对消息去重,达到producer端的exactly once。
这里还涉及到producer端的acks设置和broker端的副本数量,以及min.insync.replicas的设置。 比如producer端的acks设置如下:
- acks=0 // 消息发了就发了,不等任何响应就认为消息发送成功
- acks=1 // leader分片写消息成功就返回响应给producer
- acks=all(-1) //当acks=all, min.insync.replicas=2,就要求INSRNC列表中必须要有2个副本都写成功,才返回响应给producer,如果INSRNC中已同步副本数量不足2,就会报异常,如果没有2个副本写成功,也会报异常,消息就会认为没有写成功。
2.2 Broker 消息接收端
上文说过acks=1,表示当leader分片副本写消息成功就返回响应给producer,此时认为消息发送成功。 如果leader写成功单马上挂了,还没有将这个写成功的消息同步给其他的分片副本,那么这个分片此时的ISR列表为空, 如果unclean.leader.election.enable=true,就会发生log truncation(日志截取),同样会发生消息丢失。 如果unclean.leader.election.enable=false,那么这个分片上的服务就不可用了,producer向这个分片发消息就会抛异常。
所以我们设置min.insync.replicas=2,unclean.leader.election.enable=false,producer端的acks=all,这样发送成功的消息就绝不会丢失。
2.3 Consumer 消息消费者端
所有分片的副本都有自己的log文件(保存消息)和相同的offset值。当consumer没挂的时候,offset直接保存在内存中,如果挂了,就会发生负载均衡,需要consumer group中另外的consumer来接管并继续消费。
consumer消费消息的方式有以下2种;
consumer读取消息,保存offset,然后处理消息。 现在假设一个场景:保存offset成功,但是消息处理失败,consumer又挂了,这时来接管的consumer,就只能从上次保存的offset继续消费,这种情况下就有可能丢消息,但是保证了at most once语义。
consumer读取消息,处理消息,处理成功,保存offset。 如果消息处理成功,但是在保存offset时,consumer挂了,这时来接管的consumer也只能从上一次保存的offset开始消费,这时消息就会被重复消费,也就是保证了at least once语义。
以上这些机制的保证都不是直接一个配置可以解决的,而是你的consumer代码来完成的,只是一个处理顺序先后问题。 第一种(至多一次)对应的代码:
List<String> messages = consumer.poll();
consumer.commitSync();
processMsg(messages);
第二种(至少一次)对应的代码:
1
2
3
List<String> messages = consumer.poll();
processMsg(messages);
consumer.commitSync();
2.4 Exactly Once实现原理
Producer端的消息幂等性保证 每个Producer在初始化的时候都会被分配一个唯一的PID,Producer向指定的Topic的特定Partition发送的消息都携带一个sequence number(简称seqNum),从零开始单调递增。
Broker会将Topic-Partition对应的seqNum在内存中维护,每次接受到Producer的消息都会进行校验; 只有seqNum比上次提交的seqNum刚好大一,才被认为是合法的。比它大的,说明消息有丢失;比它小的,说明消息重复发送了。
以上说的这个只是针对单个Producer在一个session内的情况,假设Producer挂了,又重新启动一个Producer被而且分配了另外一个PID, 这样就不能达到防重的目的了,所以kafka又引进了Transactional Guarantees(事务性保证)。
2.5 Transactional Guarantees 事务性保证
2.5.1 producer端
kafka的事务性保证说的是:同时向多个TopicPartitions发送消息,要么都成功,要么都失败。
为什么搞这么个东西出来?我想了下有可能是这种例子: 用户定了一张机票,付款成功之后,订单的状态改了,飞机座位也被占了,这样相当于是 2条消息,那么保证这个事务性就是:向订单状态的Topic和飞机座位的Topic分别发送一条消息, 这样就需要kafka的这种事务性保证。
这种功能可以使得consumer offset的提交(也是向broker产生消息)和producer的发送消息绑定在一起。 用户需要提供一个唯一的全局性TransactionalId,这样就能将PID和TransactionalId映射起来,就能解决 producer挂掉后跨session的问题,应该是将之前PID的TransactionalId赋值给新的producer。
2.5.2 Consumer端
以上的事务性保证只是针对的producer端,对consumer端无法保证,有以下原因:
压实类型的topics,有些事务消息可能被新版本的producer重写 事务可能跨坐2个log segments,这时旧的segments可能被删除,就会丢消息 消费者可能寻址到事务中任意一点,也会丢失一些初始化的消息 消费者可能不会同时从所有的参与事务的TopicPartitions分片中消费消息 如果是消费kafka中的topic,并且将结果写回到kafka中另外的topic, 可以将消息处理后结果的保存和offset的保存绑定为一个事务,这时就能保证 消息的处理和offset的提交要么都成功,要么都失败。
如果是将处理消息后的结果保存到外部系统,这时就要用到两阶段提交(tow-phase commit), 但是这样做很麻烦,较好的方式是offset自己管理,将它和消息的结果保存到同一个地方,整体上进行绑定,可以参考Kafka Connect中HDFS的例子。
2.6 基本命令
查看kafka消费组偏移量
1
kafka-consumer-groups.sh --all-topics --all-groups --bootstrap-server localhost:9092 --describe
发送消息
1
kafka-console-producer.sh --broker-list localhost:9092 --topic ${Topic} //回车后,直接输入就可以了
订阅消息
1
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ${Topic}
3 客户端使用
3.1 Kafka 分区
分区的目的是实现负载均衡和高吞吐量。Kafka的消息组织方式,实际上是三级结构:主题-分区-消息。 主题下的每条消息只会保存在某一个分区中,而不会在多个分区中被保存多份。
3.2 消费者组
Consumer Group是Kafka提供的可扩展且具有容错性的消费者机制。Consumer Group下可以有一个或者多个Consumer实例;Group ID用于作为Group标识;Consumer Group订阅的主题的某个分区只能分配给组内的唯一一个consumer实例消费。说明消费实例数量 > 主题分区数,就会有消费实例无事可做了。
4 消息投递的可靠性保证
4.1 消息中间件
- 消息中间件 收到接收者确认处理完毕后,才能删除消息。不能根据网络层判断,一定要根据应用层的回应。
4.2 消息发送端——失败的补发
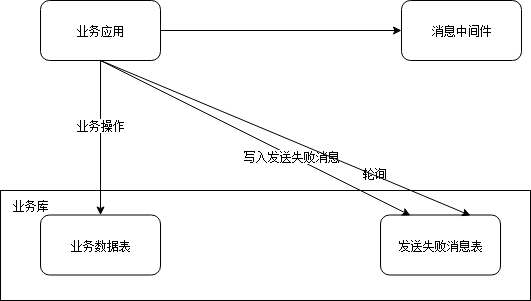
从业务数据上进行消息补发才是最彻底的容灾手段。
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
props.put(ProducerConfig.ACKS_CONFIG, "all");
producer = new KafkaProducer<>(props, new StringSerializer(), new StringSerializer());
ProducerRecord<String, Object> record = new ProducerRecord(topic, "String");
producer.send(record, new KafkaSendCallback());
}
public class KafkaSendCallback implements Callback {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("AsynchronousProducer call Success:");
return;
}
if ((exception instanceof InvalidTopicException) ||
(exception instanceof RecordBatchTooLargeException) ||
(exception instanceof RecordTooLargeException) ||
(exception instanceof UnknownServerException)
) {
System.out.println("AsynchronousProducer failed: the message will never be sent");
} else if ((exception instanceof CorruptRecordException) ||
(exception instanceof InvalidMetadataException) ||
(exception instanceof NotEnoughReplicasAfterAppendException) ||
(exception instanceof NotEnoughReplicasException) ||
(exception instanceof OffsetOutOfRangeException) ||
(exception instanceof TimeoutException) ||
(exception instanceof UnknownTopicOrPartitionException)
) {
System.out.println("AsynchronousProducer failed: may be covered by increasing #.retries");
}
}
}
- 一定要使用有callback的send接口,callback中处理发送失败的消息,可以区分消息是可以重发还是无法发送,将println换成对应的处理方式,如存数据库,然后定时补发。
- 设置acks = all, acks 是Producer的一个参数,戴白哦了你对“已提交”消息的定义,如果设置成all, 则表明所有副本Broker都要接收到消息,消息才算“已提交”。
- 设置retries > 0, 让Producer进行重试消息发送。
- 设置relication.factor >=3, 这是Broker端的参数,将消息多保存积分
- 是指min.insync.replicas > 1, 这个也是Broker的擦书,控制消息至少要被写入多少个副本才算“已提交”。
4.3 消息接收者
- 不能在收到消息后,业务没有完成时就确认消息。
- 不能捕获异常,然后确认消息成功。
如果消息处理成功,但是在保存offset时,consumer挂了,这时来接管的consumer也只能 从上一次保存的offset开始消费,这时消息就会被重复消费,也就是保证了at least once语义。
props.put("enable.auto.commit", "false"); // 不自动提交offset
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test"));
while (true) {
//读取消息
ConsumerRecords<String, String> records = consumer.poll(1000);
//消息处理
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
//保存offset
consumer.commitSync();
}
5 保序
按消息键保序策略:
- Kafka同一个topic下的同一个partion是顺序的。
- Kafka允许为每条消息定义消息键,简称Key。一旦消息被定义了Key,那么你就可以保证同一个Key的所有消息都进入到相同的分区里面。
- kafka保证了一个partion只能被一个消费组里面的一个consumer消费
例如采集的是设备状态,因为设备状态是一段持续时间,如果乱序,设备状态持续的时间就不对了,所以是需要保序的,那么就需要将设备ID 取余,如果只有2个Partion,那么ID % 2作为可以发送到broker是比较合适的。
消息消费也需要是单线程消费,多实例的时候,需要设置消费组,kafka保证了一个partion只能被一个消费组里面的一个consumer消费,这样就保证了有序性。
6 消息堆积
消费者的消费速度小于生产者的产生速度,所以导致了消息堆积
6.1 优化消费端
如数据库查询慢,数据没有加索引等。
6.2 重复消费
consumer在堆积的消息队列中拿出部分消息来消费,如果生产者一次产生的数据量过大, 那么consumer是有可能在规定的时间内(session.timeout.ms)消费不完的。如果设置的是自动提交(enable.auto.commit),就会出现提交失败的情况,提交失败就会回滚,这部分数据就相当于没有被消费过,然后consumer继续去拿数据如果还没消费完就还是回滚,这样循环下去。
6.3 通过并发提高消费的速度
6.3.1 多线程+多KafkaConsumer实例方案
消费者程序启动多个线程,每个线程为父专属的KafkaConsumer实例,每个线程负责完成的消息获取和处理流程。
- 优点: 实现简单,并且能保证消息消费的顺序
- 缺点: 线程数受限与订阅主题的分区数量。如果线程处理的慢,造成消费停滞,容易出现Rebalance
6.3.2 单线程+单KafkaConsumer实例+消息处理线程池方案
消费者程序通过使用单线程或者多线程获取消息,同时多个多个消费线程执行消息处理逻辑。
- 优点:拥有很高的扩展性,根据需要扩展worker线程就可以了。
- 缺点:消息获取和消费分开了,无法保证消费顺序。唯一提交变得比较困难,容易导致重复消费。
7 消息重复
7.1 重复的原因
- 消息发送端没有收到“成功”的返回结果。
- 消息中间件不能及时更新投递状态。
7.2 解决办法
7.2.1 消息接收者消息处理是幂等操作。
如:
UPDATE stat_table set count = 10 where id = 1
不需要特殊处理。
7.2.2 操作不是幂等操作
如:
UPDATE stat_table set count = count + 1 where id = 1
首先优先选用幂等的方式,如果无法实现,那么可以通过redis去重:
- 发送端同时消息中增加唯一标识(如果UUID)和发送时间
- redis中存放uuid, 处理状态 (redis过期时间 = kafka消息端保存时间)
- mysql中数据uuid。
- 并发情况, 查找和更新redies操作进行加锁。
lock();
// 消费端收到消息,查找消息是否已经存在。 如果存在, 忽略此消息
if (msg时间戳 + 过期时间 < current) {
查找redis
if (uuid存在) {
if (处理状态 == done) {
通知消息队列处理完成(commitSync());
return;
}
} else {
uuid和stauts = doing写入redis
}
} else {
查找数据库;
if (uuid存在) {
通知消息处理完成(commitSync());
return;
}
}
//未收到消息或者上次收到的消息没有处理完成
业务处理;
通知消息处理完成(commitSync();
Redis_UpdateIfexist(uuid, done)
unlock();
8 扩容
如果有消息中间件应用长期不可用的话,我们就需要加入一个和它具有同样server标识的机器来代替它,或者把通过这个消息中间件进入到消息系统中但还没有完成投递的消息分给其他机器处理,也就是让另一台机器承担剩余消息的投递工作
基本的策略:
- 让向一个队列写入数据的消息发送者能够知道应该把消息写入迁移到新的队列中
- 订阅者也需要知道, 当前队列消费完数据后需要迁移到新队列去消费消息。
关键点:
- 原队列在开始扩容后需要以一个标志,即便有消息过来,也不再接收。
- 通知消息发送端新的队列位置。
- 消息接收端收到新旧2个位置,当就队列数据接收完毕后,则只关心新队列的位置,完成切换。
9 Kafka 部署
kafka是采用顺序的读写操作,使用SSD并没有太大的性能优势,kafka在软件层面实现了负载均衡,使用记性机械硬盘就可以满足kafka的线上环境。
磁盘容量,1s钟采集400次,同时支持16个网关,每条数据100字节,那么每天发送55G数据,保存2份,那么需要110G空间。同时预留10%的空间,存放3天的数据。需要363G,kafka会对数据进行压缩,算0.75,Name所需的存储空间就是273G。
带宽,对于kafka这种通过网络进行大量传输的框架而言,带宽很容易成为瓶颈, 对于千兆网络:1GBps, 按照70%用于kafka, 那么1个kafka节点可提供的带宽为700MBps, 还是16个网关那么1s中会传输640kb数据,1个kafka节点完全满足,但是为了保证kafka的高可靠性,需要至少部署3个实例节点。