1 设计前准备
尤其是多人设计数据库表的情况下,更重要。
- 整理项目中名词术语对照清单,保证设计时字段名字的统一。
- 确定不同类型字符串的长度,如name,code等
- 确定小数的位数
- 确定不同整形的应用范围
2 数据类型的选择
- 更小的通常更好,占用更少的磁盘,内存和cpu缓存。
- 简单就好。整型比字符串更好,内件时间类型比字符串好。
- 尽量避免NULL, 如果计划在列上建索引就应该尽量避免设计成为NULL的列。
2.1 整数类型
整数类型有可选的UNSIGNED属性,表示不允许负值,这大致可以使正数的上限提高一倍。有符号和无符号类型使用相同的存储空间,并且具有相同的性能,一次可以根据实际情况选择合适的类型。
Mysql可以为整数类型指定宽度,如INT(11),对大多数应用这是没有意义的,他不会限制值的合法范围,只是规定了Mysql的一些交互工具(如命令行客户端)用来显示字符的个数。对于存储和计算来时,INT(1)和INT(20)是相同的。
2.2 实数类型
在对小数进行精确计算时,必须使用DECIMAL,如储存财务数据。
2.3 字符串类型
2.3.1 VARCHAR
用于存储变长字符串,VARCHAR需要使用1或2个额外字节记录字符串的长度。如果类的长度小于等于255,只是用1个字节,否则使用2个。这也是为什么字符串的长度定义多是VARCHAR(255), 而不是VARCHAR(256)。
适合使用VARCHAR的场景:
- 字符串列的最大长度比平均长度大很多
- 列的更新很少, 碎片不是问题
VARCHAR(5)和VARCHAR(200)存储’hello’的空间开销是一样的,使用更短的列有什么优势。更长的列会消耗更多的内存,因为mysql会分配固定大小的内存块来保存内部值,所以最好的策略是值分配真正需要的空间。
2.3.2 CHAR
试用场景:
- 很短的字符串
- 所有值都接近同一长度, 如存储密码的md5值
- 经常变更的数据,定长不容易产生碎片。
2.4 日期和时间类型
DATETIME和TIMESTAMP提供两种想死的日期类型。DATETIME 8占用8个字节,TIMESTAMP占用4个字节,DATETIME保存的范围更大(1001 ~ 9999), TIMESTAMP的范围是1970~2038。除了特殊行为之外,应该尽量使用TIMESTAMP,因为空间效率更高。
2.5 特殊类型
如IPV4地址实际是32位无符号整数,不是字符串,应该使用无符号整出存储。
2.6 其他类型
- TEXT,BLOB为了存储很大的数据而设计的字符串数据类型,分别采用字符串和二进制方式存储
- 位数据类型(BIT), 指定存储的位数,应该尽量避免使用。
- SET,用于一个列存储多个值。
- ENUM类型
3 主键选择
数据库设计主要是对实体和关系的设计,实体就是表,关系就是外键。对于一个表,由两部分组成:主键和属性。主键是表中每一行数据的唯一标识。主键是定位到一条记录并且确保不会重复存储的逻辑机制,更方便的检索和管理数据。由于主键常常用于检索数据,被外键引用来建立表与表之间的关系,所以主键设计的好坏将会严重影响数据操作的性能。
主键可以分为业务主键和代理主键:
业务主键可以是一个字段单独做主键, 也可以是多个字段组合在一起做组成联合主键。使用表中的业务字段作为主键,这种表并不多, 因为要保证该字段长久的具有行记录唯一的特点。一旦修改非常麻烦(比如身份证,15位变18位),如果作为其他表的外键就需要同步修改。联合主键有不只1列,如果会被其他表作为外键,就需要存多列。业务主键建议尽量不要使用,本文就不考虑业务主键了。
3.1 代理主键
新增一列与业务无关的唯一性的字段做主键,也称之为“伪主键”。引入一个对于表的域模型无意义的新列来存储一个伪值。 这一列被用作这张表的主键,从而通过它来确定表中的一条记录,即其他的列允许出现适当的重复项。
代理主键的好处:
-
消除主键(业务字段)修改引起的一致性问题 因为业务列都有修改的可能性(比如员工号,产品编号等等),如果有其他表引用该字段作为外键,要引起级联修改。
-
消除联合主键由多个字段组成引起的冗余存储 如果业务主键由多个列组成(比如上班打卡记录,由员工号+日期组成),如果有其他表引用该表的主键做外键,需要存储多个字段,造成存储空间的扩大。
-
业务主键无法实现的情况 比如有多个字段作为主键,在应用中只有这些字段全部输入后才能保存,现实中有些功能是“保存草稿”状态的,也就是说必填字段可以在没有填写的情况下实现保存,如果不采用逻辑主键的话,此功能就无法实现。
-
传递更少的参数 应用程序中不方便,比如像查询一个对象的明细信息,如果采用关联主键,可能需要传递多个参数才能确定一条数据(更方便地实现业务功能)
3.2 常用代理主键的生成策略
3.2.1 自增主键
数据库提供的自增数值型字段作为自增主键,它的优点是:
- 数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利;
- 数字型,占用空间小,易排序,在程序中传递也方便;
- 如果通过非系统增加记录时,可以不用指定该字段,不用担心主键重复问题。
其实它的缺点也就是来自其优点,缺点如下:
-
因为自动增长,在手动要插入指定ID的记录时会显得麻烦,尤其是当系统与其它系统集成时,需要数据导入时,很难保证原系统的ID不发生主键冲突(前提是老系统也是数字型的)。特别是在新系统上线时,新旧系统并行存在,并且是异库异构的数据库的情况下,需要双向同步时,自增主键将是你的噩梦;
-
很难处理分布式存储的数据表 MySQL(auto_increment)、SQL Server(IDENTITY)、Informix、Oracle(首先创建自增序列,接着为自增主键的表创建插入时的触发器,给自增主键ID赋值)等数据库都支持这种自增主键,这种主键在各种系统中应用广泛。
但是如果考虑到有新旧系统并存等问题,为了避免不必要的麻烦,使用自增主键要三思。
3.2.2 只考虑唯一性的主键
UUID主键或者根据业务自己生成(如基于IP,线程ID,时间戳,本机计数器等因素)唯一的ID。如果存储UUID的值,应该一出“-”符号。更好的做法是用UHEX()函数转换UUID为16字节数字,并且存储在一个BINARY(16)的列中。检索时通过HEX()函数转换为十六进制格式。
主要优点是:
- 生成管理方便——完全由算法自动生成,不需要一个权威机构来管理,在空间上和时间上具有唯一性,保证同一时间不同地方产生的数字不同。
- 系统集成方便———世界上的任何两台计算机都不会生成重复的UUID值, 所以几个系统的UUID值导到一起时,也不会发生重复。
- 数据库移植方便——UUID列可以作为字符型列转换到其它数据库中,同时将应用程序中产生的UUID值存入数据库,不会对原有数据带来影响。
- UUID的长度固定,并且相对而言较短小,非常适合于排序、标识和存储。
缺点是:
- UUID值较长,不容易记忆和输入,而且这个值是随机、无顺序的。
- UID的值有16个字节,与其它诸如4字节的整数相比要相对大一些。这意味着如果在数据库中使用键,可能会带来两方面的消极影响:存储空间增大、索引时间会慢一些。
3.3 自己生成的数字型主键
如BigInt类型。
-
单实例的情况 ID生成器和服务在同一个服务,服务启动的时候,从数据库取最大的ID,并且记录在内存中,每插入一条数据对数据进行更新。
-
多实例的情况 单独启动一个服务,按照未分表前的表名统一生成ID。 每次生成ID后,更新次ID序列的最大值。为了减少远程获取ID的开销,通过批量获取一段ID,然后缓存在本地,这样就不需要每次另一个服务获取了。如果系统挂了,那么这段ID就浪费了,一次获取的数量适量,宕机的情况有很少,这个问题基本可以忽略不计。
整数通常是最好的选择,因为性能更好。应该尽量避免使用字符串作为主键,因为会占用更多的存储空间,通常比整型满。
4 数据库设计的注意事项
- 太多的列,会导致存储数据解码到各个列的代价很高。
- 太多的关联,高性能Mysql建议不要超过12个关联,阿里的规范不能超过6个关联。
- 防止过度使用枚举。·
5 设计范式
关系数据库设计是对数据进行组织化和结构化的过程,核心问题是关系模型的设计。对于数据库规模较小的情况,我们可以比较轻松的处理数据库中的表结构。然而,随着项目规模的不断增长,相应的数据库也变得更加复杂,这时我们往往会发现我们写出来的SQL语句的是很笨拙并且效率低下的。更糟糕的是,由于表结构定义的不合理,会导致在更新数据时造成数据的不完整。因此我们需要设计更好的数据库的表结构,减少冗余的数据,借此可以提高数据库的存储效率,数据完整性和可扩展性。
简洁、结构明晰的表结构对数据库的设计是相当重要的。规范化的表结构设计,在以后的数据维护中,不会发生插入(insert)、删除(delete)和更新(update)时的异常。反之,数据库表结构设计不合理,不仅会给数据库的使用和维护带来各种各样的问题,而且可能存储了大量不需要的冗余信息,浪费系统资源。
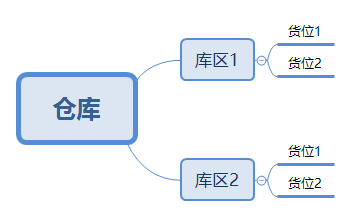
5.1 第一范式
表中字段都是单一属性的,不可再分。不满足第一范式(1NF)的数据库就不是关系数据库。
5.1.1 反例
仓库表:
| 主键 | 仓库名称 | 仓库编码 | 包含库区 |
|---|---|---|---|
| 1 | 杭州01号仓库 | hz0001 | 1,2 |
库区表:
| 主键 | 库区名称 | 库区编码 |
|---|---|---|
| 1 | 01号库区 | 0001 |
| 2 | 02号库区 | 0002 |
仓库表“包含库区”列,违反了单一属性,不可再分的原则。如果我们必须使用这些数据,那么这些查询将会十分复杂并且我也怀疑这些查询会有性能问题。
5.1.2 优化后
| 主键 | 仓库名称 | 仓库编码 |
|---|---|---|
| 1 | 杭州01号仓库 | hz0001 |
库区表:
| 主键 | 库区名称 | 库区编码 | 所属仓库 |
|---|---|---|---|
| 1 | 01号库区 | 0001 | 1 |
| 2 | 02号库区 | 0002 | 1 |
被塞满了分隔符的数据列需要特别注意,一个较好的办法是将这些字段移到另外一个表中,使用外键连接过去,便于更好的管理。
第一范式很容易满足,而且当前所有的关系数据库管理系统(DBMS)中,都已经在建表的时候强制要求有主键,其他的属性都依赖主键,唯一需要注意的是字段不可再分。
5.2 第二范式
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。
第二范式(2NF)要求实体的属性完全依赖于主关键字。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是非主属性部分依赖于主关键字。
5.3 第三范式
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。
5.4 范式和反范式
- 范式的更新操作通常比反范式要快
- 范式的主要问题是关联。
5.4.1 结合业务分析
设计是为业务服务的,如果冗余的内容基本上不变化,并且冗余后让实现更方便,性能更好,那么可以考虑适当冗余。
例如,To B的软件,需要为客户定制枚举显示的名称。一种方案每次查询关联字典表查询,另一种方案同时存放枚举的ID和值。真正的业务场景是修改枚举显示的名称是在实施的时候进行修改,所以冗余到业务表中,数据量不大,而且编码容易,性能也好。这种情况可以考虑冗余。
5.4.2 结合性能分析
如果需要插入性能更高,那么不冗余会好一些 如果需要查询性能更好,那么冗余会更满足需求一些。
6 数据库设计举例
在上面仓库的例子中,最终商品是放在货位上的,页面显示如下:

6.1 完全符合第三范式
表结构如下:
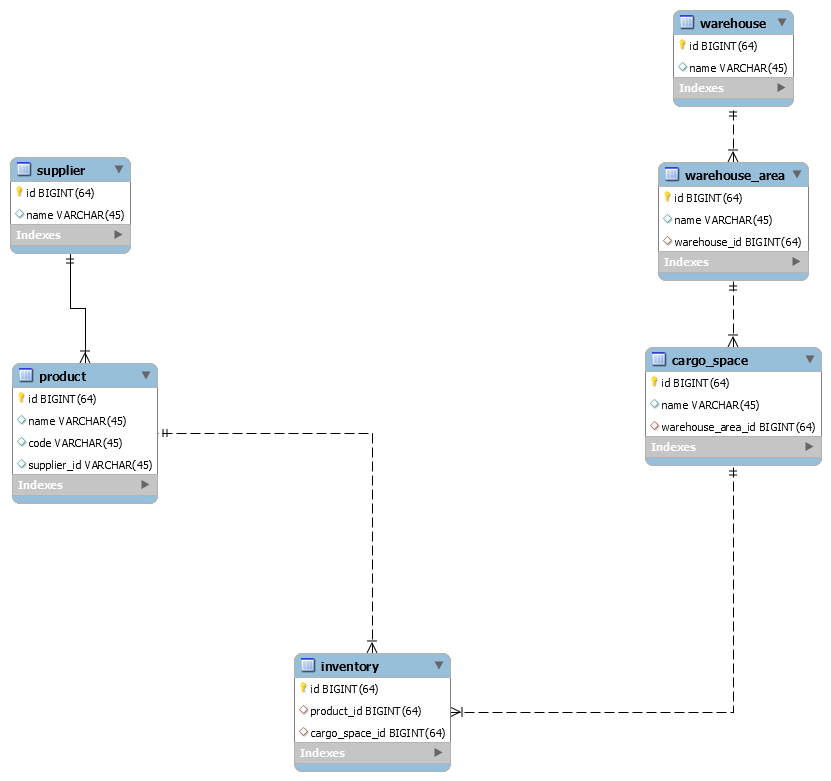
如果要满足上面的页面展示的SQL如下:
SELECT a.*,
b.product_name as product_name, b.product_code as product_code,
c.name as project_name,
d.name as cargo_space_name,
e.name as warehouse_area_name,
f.name as warehouse_name,
g.supplier_name as supplier_name, g.id as supplier_id
FROM inventory a
LEFT JOIN base_product b ON a.product_id = b.id
LEFT JOIN base_project c ON a.project_id = c.id
LEFT JOIN base_cargo_space d ON a.cargo_space_id = d.id
LEFT JOIN base_warehouse_area e ON d.warehouse_area_id = e.id
LEFT JOIN base_warehouse f ON e.warehouse_id = f.id
LEFT JOIN base_supplier g ON b.supplier_id = g.id
6.2 根据业务进行合理的冗余
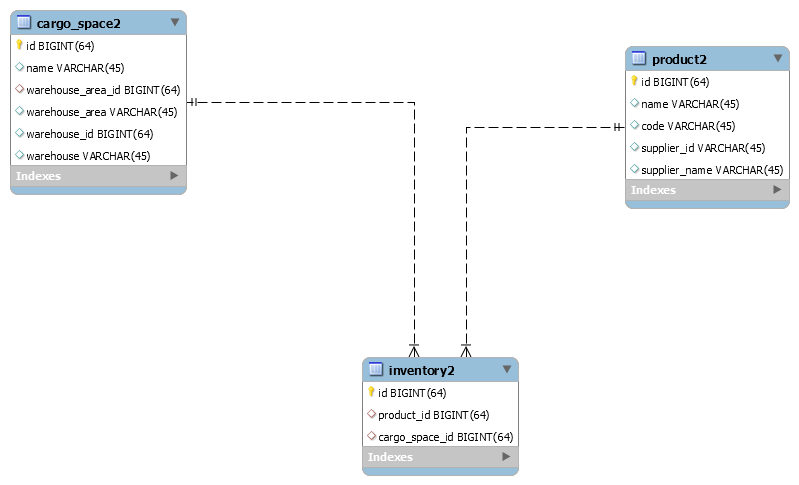
- 将supplier的信息冗余到product表
- 将仓库和库区的信息冗余到货位表
如果要满足上面的页面展示的SQL如下:
SELECT a.*,
b.product_name as product_name, b.product_code as product_code, b.supplier_name,
d.name as cargo_space_name,
d.warehouse_area_name as warehouse_area_name,
d.warehouse_name as warehouse_name
FROM inventory a
LEFT JOIN base_product b ON a.product_id = b.id
LEFT JOIN base_cargo_space d ON a.cargo_space_id = d.id
6.3 总结
合理的冗余不仅减少了联表,提高了效率。
-
表的设计和软件编码也是一样的原理,也需要满足高内聚,低耦合。产品的信息都从产品获取,货位的信息都从货位获取,不用再基于产品进行关联查询。
-
信息统一放在一个表中,数据修改,也方便,如果更新供应商的信息,只需要同时更新产品表就可以了。
7 索引
索引优化是对查询性能优化最有效的手段了,索引能够轻易将查询性能提高几个数量级。“最优”的索引有时比一个好的索引性能要好2个数量级。数据库的索引工作方式和书的目录很像,想要查找书中的某个特定主题,先查找书的目录,然后找到对应的页码。
7.1 B+树
我们日常使用innodb作为存储引擎,innodb使用B+树实现的索引。
B+树最早是从平衡二叉树演化而来的。二叉树的查找速度和比较次数都是最小的[时间复杂度O(logN)], 但是数据库的索引时存储在磁盘上的。我们利用索引查询的时候,不能把整个索引全部加载到内存,只能逐一加载每一个磁盘页。
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
每次查找数据时把磁盘IO次数控制在一个很小的数量级,最好是常数数量级。磁盘的IO次数由树的高度决定,为了减少磁盘的IO次数,我们需要把原本瘦高的树结构变得“矮胖”。
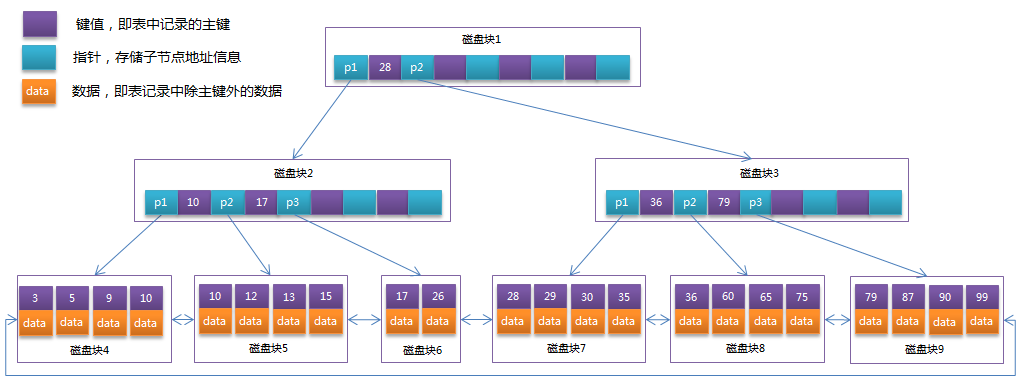
根节点中存放了指向叶子结点的指针,存储引擎根据这些指针向下层查找。通过比较节点页的值和查找页的值可以找到合适的指针进入下层子节点,这些指针实际上定义了子节点页中值的上限和下限。树的深度和表的大小直接相关。
7.2 创建高性能索引的策略
7.2.1 独立的列
查询不当的使用索引,索引不能是表达式的一部分,也不能是函数的参数,
SELECT actor_id FROM actor WHERE actor + 1 = 5
SELECT ... WHERE TO_DAYS(CURRENT_DATA) - TO_DAYS(data_col) <= 10
这2查询都无法使用actor或者data_col索引。我们需要养成简化WHERE条件的习惯, 始终将索引列单独放在比较符号的一侧。
7.2.2 前缀索引
索引很长的字符串会让索引变得大且慢,通常可以所以开始的部分字符,这样可以大大节约索引空间,从而提交索引效率。但是这降低了索引的选择性,一般情况下某个列的前缀的选择性也是最够高的。对于BLOB,TEXT或者很长的VARCHAR类型的列,必须使用前缀索引。
诀窍在于选择足够长的前缀以保证较高的选择性,同时又不能太长。可以通过:
SELECT COUNT(*) ....
SELECT COUNT(*) , LEFT(city, $n) AS pref FROM
从而找到合适的长度。
7.2.3 选择合适的顺序 (B树适用)
将选择性最高的列放到索引的最前列