1 如何阅读源代码
1.1 为什么阅读源代码
-
对代码感兴趣,顺便学习编码技巧,如作为java开发者,不阅读JDK源代码也不影响软件开发,阅读JDK的代码因为感兴趣,顺便学习编程技巧。
-
确认用法是否正确,如使用了eclipse的paho的mqtt客户端,但是没有文档明确说明它是否实现了连接池,这时候去阅读源代码确实是否需要是否需要为它实现连接池就很有必要。
-
开发和维护的代码,无论是公司的私有代码还是开源代码,那都需要把整个代码摄入阅读和理解。如基于edgex foundry做采集网关,那么需要把整个edgex框架的架构和代码深入理解。
阅读JDK的源代码对于我来说就是个人爱好,我只是做JAVA开发,并不做JDK的开发,但是对一些实现还是想知道怎么实现的,如ConcurrentHashMap是如何实现高效并发支持的。
1.2 如何阅读源代码
1.2.1 通过文档了解开源项目
如Quick Start, 快速使用开源项目。Introduction, 了解项目的基本介绍,如kafka的topic,partion,producer, consumer等
- 这个项目是干什么的
- 能解决那些问题
- 适合那些场景
- 有哪些功能
- 如何使用
1.2.2 带着问题去阅读源代码
还是通过看文档,选择设计或者实现章节,根据设计的原理和简述,不只是带着问题去读源代码。这样更容易理解源代码。以这种方式阅读源代码,每次只要话很短的时间,阅读很少的一部分源码,就能解决一个问题,得到一些收获。
2 JDK源代码阅读
2.1 如何获得JDK的源代码
可以去openjdk的官网下载,也可以直接再jdk的安装获取,例如我的jdk安装在:
1
C:\Program Files\Java\jdk1.8.0_191
src.zip就是jdk的源代码。不用纠结openjdk和oracle源代码差异有多大,oracle也会向openjdk贡献代码,对于仅仅是感兴趣阅读源代码,不是进行jdk开发的话,可以不用纠结,哪个获取容易看哪个就可以了。
2.2 HashMap
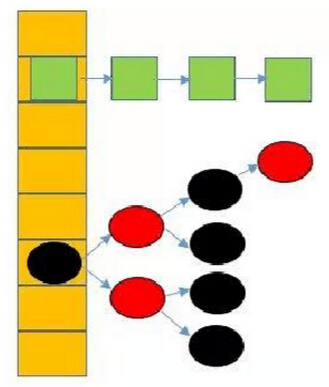
JDK8中的hashmap是基于数组和链表的拉链法实现的,当同一个hash值的链表大小超过阈值(8),会被调整成一颗红黑树。再最坏的情况下,链表查找的时间复杂度为O(n),而红黑树一直是O(logn),这样会提高HashMap的效率。
hashMap是在首次添加元素的时候才进行初始化(lazy-load原则)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbent,
boolean evit) {
Node<K,V>[] tab; Node<K,V> p; int , i;
if ((tab = table) == null || (n = tab.length) = 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == ull)
tab[i] = newNode(hash, key, value, nll);
else {
// ...
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for first
treeifyBin(tab, hash);
// ...
}
}
- 如果table 为null, resize负责初始化它。
- 如果容量 > threshold(负载因子 * 容量)时,也进行扩容。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
final Node<K,V>[] resize() {
// ...
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACIY &&
oldCap >= DEFAULT_INITIAL_CAPAITY)
newThr = oldThr << 1; // double there
// ...
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// zero initial threshold signifies using defaultsfults
newCap = DEFAULT_INITIAL_CAPAITY;
newThr = (int)(DEFAULT_LOAD_ATOR* DEFAULT_INITIAL_CAPACITY;
}
if (newThr ==0) {
float ft = (float)newCap * loadFator;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);
}
threshold = neThr;
Node<K,V>[] newTab = (Node<K,V>[])new Node[newap];
table = n;
// 移动到新的数组结构 e 数组结构
}
门限值通常以倍数进行调整(newthr = oldThr « 1), 当元素个数超过门限大小时,调整table的大小。table的容量以倍数进行调整(newCap = oldCap « 1)
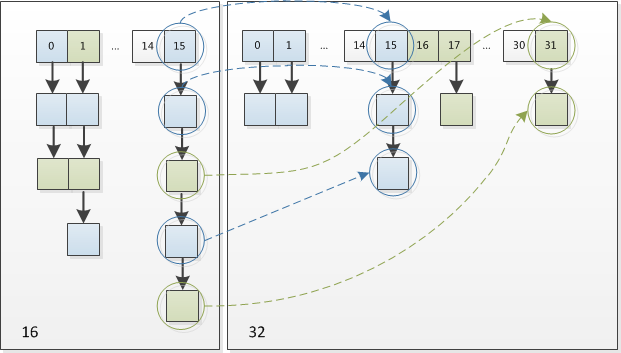
resize时,复制一个节点,然后复制此节点对应的链表和树。复制的时候分为low和high,low的放在j的位置,high放在j+oldCap位置上。 因为我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。
删除时,对于链表就是删除节点的前一个结点.next=删除节点的后一个节点。
2.3 ConcurrentHashMap
Java8之后的版本中,concurrentHashMap发生了很大的变化
-
总体结构上,它的内部存储HashMap非常相似,同样是大的桶数组+链表/红黑树。
-
内部仍然后segement定义,只是为了保证序列化时的兼容性而已,不在有任何结构上的用处。
-
数据存储利用volatile来保证可见性
-
使用CAS等操作,在特定场景进行无所操作
-
使用Unsafe,LongAdder之类的底层手段,进行极端情况的优化。
参考: https://time.geekbang.org/column/article/8137
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
// 如果发现冲突,进行 spin 等待
if ((sc = sizeCtl) < 0)
Thread.yield();
// CAS 成功返回 true,则进入真正的初始化逻辑
else if (U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
这是一个典型的 CAS 使用场景,利用 volatile 的sizeCtl作为互斥手段:如果发现竞争性的初始化,自旋在那里,等待条件恢复;否则利用CAS设置排它标志。如果成功则进行初始化;否则重试。
通过synchronized(table节点)进行同步。
现在的JDK中,synchronized已经被不断的优化,可以不再过分担心性能差异,另外,相比与ReeentrantLock,可以减少内存消耗,这是一个非常大的优势。