1 C 语言编译流程
示例代码: 源代码地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <stdio.h>
/*
* Example for compile
*/
#define PET "little hedgehog"
int main() {
printf("Hello lovely %s!\n", PET);
return 0;
}
编译命令:
1
gcc hello.c -o hello
上面的这个编译命令包含了四个阶段的处理,即预处理(也称预编译,Preprocessing)、编译(Compilation)、汇编 (Assembly)和连接(Linking)。
1.1 预处理
作用: 预处理的作用主要是读入源代码,检查包含预处理指令的语句和宏定义,并对源代码进行相应的转换。预处理过程还会删除程序中的注释和多余的空白字符。
处理对象: 预处理指令是以“#”开头的,预处理的处理对象主要包括以下方面:
- #define: 宏定义
- #运算符: #运算符作用是把跟在其后的参数转换成一个字符串
- ##运算符: ##运算符的作用用于把参数连接到一起
- 条件编译指令: #ifdef
- 头文件包含指令: #include
- 特殊符号:
__FILE__和__LINE__等
上面的hello.c文件的预处理指令是
1
gcc -E hello.c -o hello.i
1.2 编译-编译成汇编语言
编译命令:
1
gcc -S hello.i -o hello.s
1.3 汇编
作用:将上面的汇编指令编译生成目标文件
汇编命令:
1
gcc -c hello.s -o hello.o
1.4 链接
链接的主要目的是将程序的目标文件与所需要附加的目标文件链接起来,最终生成可执行文件。目标文件也包括了所需要的库文件(静态链接库和动态链接库)
链接命令:
1
gcc hello.o -o hello
最终生成的test文件就是最终系统可以执行的文件。
对于程序的编译,我们一般把它认为“编译”和“链接”两部分也足够了,这里的编译已经包括了预处理,编译成汇编语言和编译成目标文件三个步骤了。只要头文件完整,语法无误,编译一般都能通过。只要有完整的目标文件和功能库文件,链接也可以成功。只要编译通过了,链接也通过了,整个项目的编译就算完成了。
2 大小端
2.1 什么是大小端问题
(From《Computer Systems,A Programer’s Perspective》)在几乎所有的机器上,多字节对象被存储为连续的字节序列,对象的地址为所使用字节序列中最低字节地址。
-
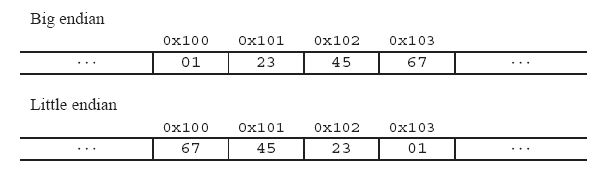
小端:某些机器选择在存储器中按照从最低有效字节到最高有效字节的顺序存储对象,这种最低有效字节在最前面的表示方式被称为小端法(little endian) 。这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放。
-
大端:某些机器则按照从最高有效字节到最低有效字节的顺序储存,这种最高有效字节在最前面的方式被称为大端法(big endian) 。这种存储模式将地址的高低和数据位权高低有效的对应起来,高地址部分权值高,低地址部分权值低,大端和我们的逻辑方法一致,符合人们的阅读和书写习惯;。
举个例子来说名大小端: 比如一个int x, 地址为0x100, 它的值为0x1234567. 则它所占据的0x100, 0x101, 0x102, 0x103地址组织如下图:
2.2 为什么会有大小端模式之分
这是因为在计算机系统中是以字节为单位的,每个地址单元都对应着一个字节,一个字节为 8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于 8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
2.3 如何区分大小端问题
方法1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <stdio.h>
int main(void)
{
int i = 1;
unsigned char *pointer;
pointer = (unsigned char *)&i;
if(*pointer)
{
printf("litttle_endian");
}
else
{
printf("big endian\n");
}
return 0;
}
C中的数据类型都是从内存的低地址向高地址扩展,取址运算”&”都是取低地址。小端方式中, i所分配的内存最小地址那个字节中就存着1,其他字节是0。大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i,则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
方法2:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <stdio.h>
int main(void)
{
union {
short a;
char ch;
} u;
u.a = 1;
if (u.ch == 1)
{
printf("Littel endian\n");
}
else
{
printf("Big endian\n");
}
}
利用联合体的特点,数据成员共享内存空间,union中元素的起始地址都是相同的——位于联合的开始。 用char来截取感兴趣的字节。
2.4 需要考虑大小端(字节顺序)的情况
- 所写的程序需要向不同的硬件平台迁移,说不定哪一个平台是大端还是小端,为了保证可移植性,一定提前考虑好。
- 在不同类型的机器之间通过网络传送二进制数据时。 一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反之时,接受程序会发现,字(word)里的字节(byte)成了反序的。为了避免这类问 题,网络应用程序的代码编写必须遵守已建立的关于字节顺序的规则,以确保发送方机器将它的内部表示转换成网络标准,而接受方机器则将网络标准转换为它的内部标准。
- 当阅读表示整数的字节序列时。这通常发生在检查机器级程序时,e.g.:反汇编得到的一条指令:
80483bd: 01 05 64 94 04 08 add %eax, 0x8049464
- 当编写强转的类型系统的程序时。如写入的数据为u32型,但是读取的时候却是char型的。如:0x1234, 大端读取为12时,小端独到的是34。
2.5 提高程序的可移植性
使用宏编译
1
2
3
4
5
#ifdef LITTLE_ENDIAN
//小端的代码
#else
//大端的代码
#endif
2.6 大、小端之间的转换
2.6.1 自己编写代码将小端转换为大端
#include <stdio.h>
void show_byte(char *addr, int len)
{
int i;
for (i = 0; i < len; i++)
{
printf("%.2x \t", addr[i]);
}
printf("\n");
}
int endian_convert(int t)
{
int result;
int i;
result = 0;
for (i = 0; i < sizeof(t); i++)
{
result <<= 8;
result |= (t & 0xFF);
t >>= 8;
}
return result;
}
int main(void)
{
int i;
int ret;
i = 0x1234567;
show_byte((char *)&i, sizeof(int));
ret = endian_convert(i);
show_byte((char *)&ret, sizeof(int));
return 0;
}
2.6.2 Linux 库函数
本地字节序转换为网络序:
- htons – 将short从本地字节序转换为网路字节序
- htonl – 将long从本地字节序转换为网路字节序
网络序转化为本地字节序:
- ntohs()–将short从网络字节序转换为本地字节序
- ntohl()–将long从网络字节序转换为本地字节序
3 字节对齐
3.1 简介
3.1.1 什么是字节对齐
现代计算机中,内存空间按照字节划分,理论上可以从任何起始地址访问任意类型的变量。但实际中在访问特定类型变量时经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序一个接一个地存放,这就是对齐。
3.1.2 对齐的原因和作用
不同硬件平台对存储空间的处理上存在很大的不同。某些平台对特定类型的数据只能从特定地址开始存取,而不允许其在内存中任意存放。例如Motorola 68000 处理器不允许16位的字存放在奇地址,否则会触发异常,因此在这种架构下编程必须保证字节对齐。
但最常见的情况是,如果不按照平台要求对数据存放进行对齐,会带来存取效率上的损失。比如32位的Intel处理器通过总线访问(包括读和写)内存数据。每个总线周期从偶地址开始访问32位内存数据,内存数据以字节为单位存放。如果一个32位的数据没有存放在4字节整除的内存地址处,那么处理器就需要2个总线周期对其进行访问,显然访问效率下降很多。
因此,通过合理的内存对齐可以提高访问效率。为使CPU能够对数据进行快速访问,数据的起始地址应具有“对齐”特性。比如4字节数据的起始地址应位于4字节边界上,即起始地址能够被4整除。
此外,合理利用字节对齐还可以有效地节省存储空间。但要注意,在32位机中使用1字节或2字节对齐,反而会降低变量访问速度。因此需要考虑处理器类型。还应考虑编译器的类型。在VC/C++和GNU GCC中都是默认是4字节对齐。
3.1.3 对齐的分类和准则
主要基于Intel X86架构介绍结构体对齐和栈内存对齐,位域本质上为结构体类型。
对于Intel X86平台,每次分配内存应该是从4的整数倍地址开始分配,无论是对结构体变量还是简单类型的变量
3.2 结构体
在C语言中,结构体是种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构体、联合等)的数据单元。编译器为结构体的每个成员按照其自然边界(alignment)分配空间。各成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
字节对齐的问题主要就是针对结构体。
1
2
3
4
5
6
7
8
9
10
11
struct A{
int a;
char b;
short c;
};
struct B{
char b;
int a;
short c;
};
已知32位机器上各数据类型的长度为:char为1字节、short为2字节、int为4字节、long为4字节、float为4字节、double为8字节。那么上面两个结构体大小如何呢?
结果是:sizeof(strcut A)值为8;sizeof(struct B)的值却是12。
结构体A中包含一个4字节的int数据,一个1字节char数据和一个2字节short数据;B也一样。按理说A和B大小应该都是7字节。之所以出现上述结果,就是因为编译器要对数据成员在空间上进行对齐。
3.2.1 对齐准则
先来看四个重要的基本概念:
- 数据类型自身的对齐值:char型数据自身对齐值为1字节,short型数据为2字节,int/float型为4字节,double型为8字节。
- 结构体或类的自身对齐值:其成员中自身对齐值最大的那个值。
- 指定对齐值:#pragma pack (value)时的指定对齐值value。
- 数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小者,即有效对齐值=min{自身对齐值,当前指定的pack值}。
基于上面这些值,就可以方便地讨论具体数据结构的成员和其自身的对齐方式。
其中,有效对齐值N是最终用来决定数据存放地址方式的值。有效对齐N表示“对齐在N上”,即该数据的“存放起始地址%N=0”。而数据结构中的数据变量都是按定义的先后顺序存放。第一个数据变量的起始地址就是数据结构的起始地址。结构体的成员变量要对齐存放,结构体本身也要根据自身的有效对齐值圆整(即结构体成员变量占用总长度为结构体有效对齐值的整数倍)。
以此分析3.1.1节中的结构体B:
假设B从地址空间0x0000开始存放,且指定对齐值默认为4(4字节对齐)。成员变量b的自身对齐值是1,比默认指定对齐值4小,所以其有效对齐值为1,其存放地址0x0000符合0x0000 % 1=0。成员变量a自身对齐值为4,所以有效对齐值也为4,只能存放在起始地址为0x0004 ~ 0x0007四个连续的字节空间中,符合0x0004 % 4=0且紧靠第一个变量。变量c自身对齐值为2,所以有效对齐值也是2,可存放在0x0008~0x0009两个字节空间中,符合0x0008%2=0。所以从0x0000~0x0009存放的都是B内容。
再看数据结构B的自身对齐值为其变量中最大对齐值(这里是b)所以就是4,所以结构体的有效对齐值也是4。根据结构体圆整的要求, 0x0000~0x0009=10字节,(10+2)%4=0。所以0x0000A~0x000B也为结构体B所占用。故B从0x0000到0x000B 共有12个字节,sizeof(struct B)=12。
之所以编译器在后面补充2个字节,是为了实现结构数组的存取效率。试想如果定义一个结构B的数组,那么第一个结构起始地址是0没有问题,但是第二个结构呢?按照数组的定义,数组中所有元素都紧挨着。如果我们不把结构体大小补充为4的整数倍,那么下一个结构的起始地址将是0x0000A,这显然不能满足结构的地址对齐。因此要把结构体补充成有效对齐大小的整数倍。其实对于char/short/int/float/double等已有类型的自身对齐值也是基于数组考虑的,只是因为这些类型的长度已知,所以他们的自身对齐值也就已知。
上面的概念非常便于理解,不过个人还是更喜欢下面的对齐准则。结构体字节对齐的细节和具体编译器实现相关,但一般而言满足三个准则:
- 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
- 结构体每个成员相对结构体首地址的偏移量(offset)都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节(internal adding);
- 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节{trailing padding}。
对于以上规则的说明如下:
- 第一条:编译器在给结构体开辟空间时,首先找到结构体中最宽的基本数据类型,然后寻找内存地址能被该基本数据类型所整除的位置,作为结构体的首地址。将这个最宽的基本数据类型的大小作为上面介绍的对齐模数。
- 第二条:为结构体的一个成员开辟空间之前,编译器首先检查预开辟空间的首地址相对于结构体首地址的偏移是否是本成员大小的整数倍,若是,则存放本成员,反之,则在本成员和上一个成员之间填充一定的字节,以达到整数倍的要求,也就是将预开辟空间的首地址后移几个字节。
- 第三条:结构体总大小是包括填充字节,最后一个成员满足上面两条以外,还必须满足第三条,否则就必须在最后填充几个字节以达到本条要求。
1
2
3
4
5
6
7
struct A {
char a;
short b;
char c;
int d;
char e[3];
};
下面来具体分析:
- 首先char a占用1个字节,没问题。
- short b本身占用2个字节,根据上面准则2,需要在b和a之间填充1个字节。
- char c占用1个字节,没问题。
- int d本身占用4个字节,根据准则2,需要在d和c之间填充3个字节。
- char e[3];本身占用3个字节,根据原则3,需要在其后补充1个字节。
因此,sizeof(A) = 1 + 1(填充) + 2 + 1 + 3(填充) + 4 + 3 + 1(填充) = 16字节。
4 位域
某些信息在存储时,并不需要占用一个完整的字节,而只需占几个或一个二进制位。例如在存放一个开关量时,只有0和1两种状态,用一位二进位即可。为了节省存储空间和处理简便,C语言提供了一种数据结构,称为“位域”或“位段”。
位域是一种特殊的结构成员或联合成员(即只能用在结构或联合中),用于指定该成员在内存存储时所占用的位数,从而在机器内更紧凑地表示数据。每个位域有一个域名,允许在程序中按域名操作对应的位。这样就可用一个字节的二进制位域来表示几个不同的对象。
1
2
3
4
5
struct
{
unsigned int widthValidated : 1;
unsigned int heightValidated : 1;
} status;
现在,上面的结构中,status 变量将占用4个字节的内存空间,但是只有 2 位被用来存储值。如果您用了32 个变量,每一个变量宽度为1位,那么 status 结构将使用4个字节,但只要您再多用一个变量,如果使用了33个变量,那么它将分配内存的下一段来存储第33个变量,这个时候就开始使用8个字节。
5 防止重复包含
1
2
3
4
5
6
7
8
9
//方式一:
#ifndef _SOMEFILE_H_
#define _SOMEFILE_H_
//.......... // 一些声明语句
#endif
//方式二:
#pragma once
//... ... // 一些声明语句
pragma once由编译器提供保证: 同一个文件不会被编译多次。注意这里所说的“同一个文件”是指物理上的一个文件,而不是指内容相同的两个文件。 带来的好处是,你不必再费劲想个宏名了,当然也就不会出现宏名碰撞引发的奇怪问题。对应的缺点就是如果某个头文件有多份拷贝,本方法不能保证他们不被重复包含。当然,相比宏名碰撞引发的“找不到声明”的问题,重复包含更容易被发现并修正。
6 内存布局
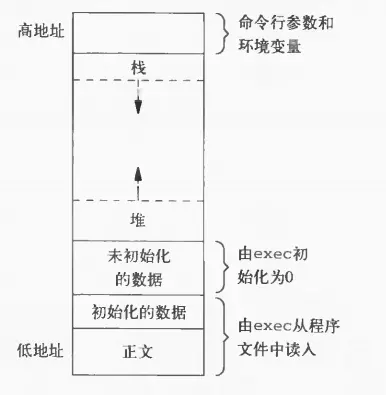
- 正文段(Text Segment),保存CPU将要执行的机器指令。文本段是可共享的,所以某个程序多次执行时,对应的文本段只需要在内存中存有一份拷贝。文本段是只读的(read-only),防止程序的指令被修改。
- 初始化数据段(initialized data segment),保存程序中被初始化的全局变量(定义在任何函数之外)。例如:int maxcount = 99; 全局变量变量maxcount被保存在初始化数据段。
- 未初始化数据段(uninitialized data segment),也被称为BSS(block started by symbol),这个段中的数据在程序执行之前被内核初始化为0或者null。;例如定义一个全局变量(定义在任何函数之外),long sum[1000]; 该变量保存在未初始化数据段中。
- 栈(Stack):存储临时变量,函数相关信息。当一个函数被调用时,返回地址、调用者相关信息(如寄存器信息)会被保存在栈中。该被调用的函数会在栈上分配一部分空间保存它的临时变量。函数的递归调用也是应用这个原理。每一次函数调用自己,都会保存当前函数的信息,然后再栈上开辟一个新的空间用于保存该次函数的信息,和以前的函数并没有影响。
- 堆(Heap):动态内存分配位置。堆的位置位于未初始化数据段和栈的中间。
7 static 作用
7.1 隐藏
当我们同时编译多个文件时,所有未加static前缀的全局变量和函数都具有全局可见性。如果加了static,就会对其它源文件隐藏。利用这一特性可以在不同的文件中定义同名函数和同名变量,而不必担心命名冲突。
7.2 持久性
static变量存放在静态存储区,所以它具备变量内容的持久性。
- static全局变量与普通的全局变量有什么区别 ?
全局变量(外部变量)的说明之前再冠以static 就构成了静态的全局变量。 全局变量本身就是静态存储方式, 静态全局变量当然也是静态存储方式。 这两者在存储方式上并无不同。 这两者的区别在于非静态全局变量的作用域是整个源程序, 当一个源程序由多个源文件组成时,非静态的全局变量在各个源文件中都是有效的。 而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效, 在同一源程序的其它源文件中不能使用它。由于静态全局变量的作用域局限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其它源文件中引起错误。 static全局变量只初使化一次,防止在其他文件单元中被引用;
- static局部变量和普通局部变量有什么区别
把局部变量改变为静态变量后是改变了它的存储方式即改变了它的生存期。把全局变量改变为静态变量后是改变了它的作用域,限制了它的使用范围。 static局部变量只被初始化一次,下一次依据上一次结果值;
- static函数与普通函数有什么区别?
static函数与普通函数作用域不同,仅在本文件。只在当前源文件中使用的函数应该说明为内部函数(static修饰的函数),内部函数应该在当前源文件中说明和定义。对于可在当前源文件以外使用的函数,应该在一个头文件中说明,要使用这些函数的源文件要包含这个头文件. static函数在内存中只有一份,普通函数在每个被调用中维持一份拷贝。
8 epoll 和 select poll的区别
8.1 select
单个进程就可以同时处理多个网络连接的io请求(同时阻塞多个io操作)。基本原理就是程序呼叫select,然后整个程序就阻塞了,这时候,kernel就会轮询检查所有select负责的fd,当找到一个client中的数据准备好了,select就会返回,这个时候程序就会系统调用,将数据从kernel复制到进程缓冲区。
8.2 Poll介绍
poll的原理与select非常相似,差别如下:
描述fd集合的方式不同,poll使用 pollfd 结构而不是select结构fd_set结构,所以poll是链式的,没有最大连接数的限制 poll有一个特点是水平触发,也就是通知程序fd就绪后,这次没有被处理,那么下次poll的时候会再次通知同个fd已经就绪。
8.3 select的缺点
根据fd_size的定义,它的大小为32个整数大小(32位机器为32*32,所有共有1024bits可以记录fd),每个fd一个bit,所以最大只能同时处理1024个fd
每次要判断【有哪些event发生】这件事的成本很高,因为select(poll也是)采取主动轮询机制
-
每一次呼叫 select( ) 都需要先从 user space把 FD_SET复制到 kernel(约线性时间成本) 为什么 select 不能像epoll一样,只做一次复制就好呢? 每一次呼叫 select()前,FD_SET都可能更动,而 epoll 提供了共享记忆存储结构,所以不需要有 kernel 與 user之间的数据沟通
-
然后kernel还要轮询每个fd,约线性时间
假设现实中,有1百万个客户端同时与一个服务器保持着tcp连接,而每一个时刻,通常只有几百上千个tcp连接是活跃的,这时候我们仍然使用select/poll机制,kernel必须在搜寻完100万个fd之后,才能找到其中状态是active的,这样资源消耗大而且效率低下。
8.4 epoll
事件驱动
- int epoll_create(int size); //建立一個 epoll 对象,并传回它的id
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); //事件注册函数,将需要监听的事件和需要监听的fd交给epoll对象
- int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout); // 等待注册的事件被触发或者timeout发生
epoll解决的问题:
- epoll没有fd数量限制
- epoll没有这个限制,我们知道每个epoll监听一个fd,所以最大数量与能打开的fd数量有关,一个g的内存的机器上,能打开10万个左右
- epoll不需要每次都从user space 将fd set复制到内核kernel,epoll在用epoll_ctl函数进行事件注册的时候,已经将fd复制到内核中,所以不需要每次都重新复制一次
8.5 epoll和select/poll区别
- select 和 poll 都是主动轮询机制,需要轮询每一个 FD;
- epoll是被动触发方式,给fd注册了相应事件的时候,我们为每一个fd指定了一个回调函数,当数据准备好之后,就会把就绪的fd加入一个就绪的队列中,epoll_wait的工作方式实际上就是在这个就绪队列中查看有没有就绪的fd,如果有,就唤醒就绪队列上的等待者,然后调用回调函数。
- 虽然epoll和poll都需要查看是否有fd就绪,但是epoll之所以是被动触发,就在于它只要去查找就绪队列中有没有fd,就绪的fd是主动加到队列中,epoll不需要一个个轮询确认。
换一句话讲,就是select和poll只能通知有fd已经就绪了,但不能知道究竟是哪个fd就绪,所以select和poll就要去主动轮询一遍找到就绪的fd, 随着连接数越多,性能越差。而epoll则是不但可以知道有fd可以就绪,而且还具体可以知道就绪fd的编号,所以直接找到就可以,不用轮询。
8.6 水平触发与边缘触发
8.6.1 水平触发(level-trggered)
- 只要文件描述符关联的读内核缓冲区非空,有数据可以读取,就一直发出可读信号进行通知,
- 当文件描述符关联的内核写缓冲区不满,有空间可以写入,就一直发出可写信号进行通知
8.6.2 边缘触发(edge-triggered)
- 当文件描述符关联的读内核缓冲区由空转化为非空的时候,则发出可读信号进行通知,
- 当文件描述符关联的内核写缓冲区由满转化为不满的时候,则发出可写信号进行通知
8.6.3 两者的区别
水平触发是只要读缓冲区有数据,就会一直触发可读信号,而边缘触发仅仅在空变为非空的时候通知一次,举个例子:
读缓冲区刚开始是空的,读缓冲区写入2KB数据
- 水平触发和边缘触发模式此时都会发出可读信号
- 收到信号通知后,读取了1kb的数据,读缓冲区还剩余1KB数据
- 水平触发会再次进行通知,而边缘触发不会再进行通知
所以边缘触发需要一次性的把缓冲区的数据读完为止,也就是一直读,直到读到EGAIN(EGAIN说明缓冲区已经空了)为止,因为这一点,边缘触发需要设置文件句柄为非阻塞。
ET模式在很大程度上减少了epoll事件被重复触发的次数,因此效率要比LT模式高。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。
9. 动态链接库
linux支持2中方式加载:
- 加载应用程序时
- 应用程序运行时绑定
多个程序同时使用一个共享库,只会在内存上占用一份内存。
9.1 符号重定位。
c/c++ 程序的编译是以文件为单位进行的,因此每个 c/cpp 文件也叫作一个编译单元(translation unit), 源文件先是被编译成一个个目标文件, 再由链接器把这些目标文件组合成一个可执行文件或库。链接的过程,其核心工作是解决模块间各种符号(变量,函数)相互引用的问题,对符号的引用本质是对其在内存中具体地址的引用,因此确定符号地址是编译,链接,加载过程中一项不可缺少的工作,这就是所谓的符号重定位。本质上来说,符号重定位要解决的是当前编译单元如何访问「外部」符号这个问题。
因为编译是以源文件为单位进行的,编译器此时并没有一个全局的视野,因此对一个编译单元内的符号它是无力确定其最终地址的,而对于可执行文件来说,在现代操作系统上,程序加载运行的地址是固定或可以预期的(fPIE暂不提),因此在链接时,链接器可以直接计算分配该文件内各种段的绝对或相对地址。所以对于可执行文件来说,符号重定位是在链接时完成的(如果可执行文件引用了动态库里的函数,则情况稍有不同)。但对于动态链接库来说,因为动态库的加载是在运行时,且加载的地址不固定,因此没法事先确定该模块的起始地址,所以对动态库的符号重定位,只能推迟。
符号重定位既指在当前目标文件内进行重定位,也包括在不同目标文件,甚至不同模块间进行重定位,这里面有什么不同吗? 如果是同一个目标文件内,或者在同一个模块内,链接后,各个符号的相对地址就已经确定了,看起来似乎不用非得要知道最后的绝对地址才能引用这些符号,这说起来好像也有道理,但事实不是这样,x86 上 mov 之类访问程序中数据段的指令,它要求操作数是绝对地址,而对于函数调用,虽然是以相对地址进行调用,但计算相对地址也只限于在当前目标文件内进行,跨目标文件跨模块间的调用,编译期也是做不到的,只能等链接时或加载时才能进行相对地址的计算,因此重定位这个过程是不能缺少的,事实上目前来说,对于动态链接即使是当前目标文件内,如果是全局非静态函数,那么它也是需要进行重定位的,当然这里面有别的原因,比如说使得能实现 LD_PRELOAD 的功能等。
9.2 链接时符合重定位
目标文件里的 .txt 段地址从 0 开始,其中地址为7的指令用于把参数 a 放到寄存器 %eax 中,而地址 a 处的指令则把 %eax 中的内容与 g_share 相加,注意这里 g_share 的地址为:0(%rip). 显然这个地址是错的,编译器当前并不知道 g_share 这个变量最后会被分配到哪个地址上,因此在这儿只是随便用一个假的来代替,等着到接下来链接时,再把该处地址进行修正。那么,链接器怎么知道目标文件中哪些地方需要修正呢?很简单,编译器编译文件时时,会建立一系列表项,用来记录哪些地方需要在重定位时进行修正,这些表项叫作“重定位表”(relocatioin table)。
链接器在把目标文件合并成一个可执行文件并分配好各段的加载地址后,就可以重新计算那些需要重定位的符号的具体地址了。
9.3 加载时符号重定位
当我们使用动态链接来构建程序时,这些符号重定位问题是怎么解决的呢?
目前来说,Linux 下 ELF 主要支持两种方式:加载时符号重定位及地址无关代码。地址无关代码接下来会讲,对于加载时重定位,其原理很简单,它与链接时重定位是一致的,只是把重定位的时机放到了动态库被加载到内存之后,由动态链接器来进行重定位,最终修改为正确的地址。这看起来与静态链接时进行重定位是一样的过程,但实现上有几个关键的不同之处:
因为不允许对可执行文件的代码段进行加载时符号重定位(动态库中的代码段可以在重定位期间被修改,参看DF_TEXTREL),因此如果可执行文件引用了动态库中的数据符号,则在该可执行文件内对符号的重定位必须在链接阶段完成,为做到这一点,链接器在构建可执行文件的时候,会在当前可执行文件的数据段里分配出相应的空间来作为该符号真正的内存地址,等到运行时加载动态库后,再在动态库中对该符号的引用进行重定位:把对该符号的引用指向可执行文件数据段里相应的区域。
ELF 文件对调用动态库中的函数采用了所谓的”延迟绑定”(lazy binding)策略, 只有当该函数在其第一次被调用发生时才最终被确认其真正的地址,因此我们不需要在调用动态库函数的地方直接填上假的地址,而是使用了一些跳转地址作为替换,这样一来连修改动态库和可执行程序中的相应代码都不需要进行了,当然延迟绑定的目的不是为了这个。
至此,我们可以发现加载时重定位实际上是一个重新修改动态库中数据符号地址的过程(函数符号的地址因为延迟绑定的存在不需要在代码段中重定位),但我们知道,不同的进程即使是对同一个动态库也很可能是加载到不同地址上,因此当以加载时重定位的方式来使用动态库时,该动态库就没法做到被各个进程所共享,而只能在每个进程中 copy 一份:因为符号重定位后,该动态库与在别的进程中就不同了,可见此时动态库节省内存的优势就不复存在了。
9.4 地址无关代码(PIC, position independent code)
从前面的介绍我们知道装载时重定位有重大的缺点:
- 它不能使动态库的指令代码被共享。
- 程序启动加载动态库后,对动态库中的符号引用进行重定位会比较花时间,特别是动态库多且复杂的情况下。
为了克服这些缺陷,ELF引用了一种叫作地址无关代码的实现方案,该解决方案通过对变量及函数的访问加一层跳转来实现,非常的灵活。
9.4.1 模块内部符号的访问
模块内部符号在这里指的是:static 类型的变量与函数,这种类型的符号比较简单,对于 static 函数来说,因为在动态库编译完后,它在模块内的相对地址就已经确定了,而 x86 上函数调用只用到相对地址,因此此时根本连重定位都不需要进行,编译时就能确定地址,稍微麻烦一点的是访问数据,因为访问数据需要绝对地址(特指 x86),但动态库未被加载时,绝对地址是没法得知的,怎么办呢?
ELF 在这里使用了一个小技巧,根据当前 IP 值来动态计算数据的绝对地址,它的原理很简单,当动态库编译好之后,库中的数据段,代码段的相对位置就已经固定了,此时对任意一条指令来说,该指令的地址与数据段的距离都是固定的,那么,只要程序在运行时获取到当前指令的地址,就可以直接加上该固定的位移,从而得到所想要访问的数据的绝对地址了。
9.4.2 模块间符号的访问
模块间的符号访问比模块内的符号访问要麻烦很多,因为动态库运行时被加载到哪里是未知的,为了能使得代码段里对数据及函数的引用与具体地址无关,只能作一层跳转,ELF 的做法是在动态库的数据段中加一个表项,叫作 GOT(global offset table), GOT 表格中放的是数据全局符号的地址,该表项在动态库被加载后由动态加载器进行初始化,动态库内所有对数据全局符号的访问都到该表中来取出相应的地址,即可做到与具体地址了,而该表作为动态库的一部分,访问起来与访问模块内的数据是一样的。